HLS流媒体协议实际上就是将视频文件切成一系列很短的小视频片段文件,一般为TS文件,即”Transport Stream”的缩写,特点就是要求从视频流的任一片段开始都是可以独立解码的。也就是说直接从服务器下载TS文件,不用经过任何处理就能用常见的播放器播放。通俗的说,HLS协议使我们在网上看电影时能够边下边播,不必把完整的电影下载完再播放,类似于迅雷的边下边播。同时HLS也有一定强度的资源保护能力,因为如果你想把电影下载到本地的话,一般人只能下载一段几秒钟的视频碎片,稍微动手能力强的能够下载一批几秒钟的视频碎片,再强一点的才能够将这一批视频碎片组成一个完成的电影。
学习的需要,用Python写了一个批量下载TS碎片的脚本,仅供大家参考。
原理:
1 先在网站上找到视频地址,即m3u8的uri
这要自己动手找,不同的网站有不同的策略,有些还会隐藏起来,我这里以一个电影网站为例说明一个常用的方法—调试JS
用chrome浏览器打开一个视频网页,按F12进入控制台模式。观察发现网页播放器的初始化过程在一个share.js文件里
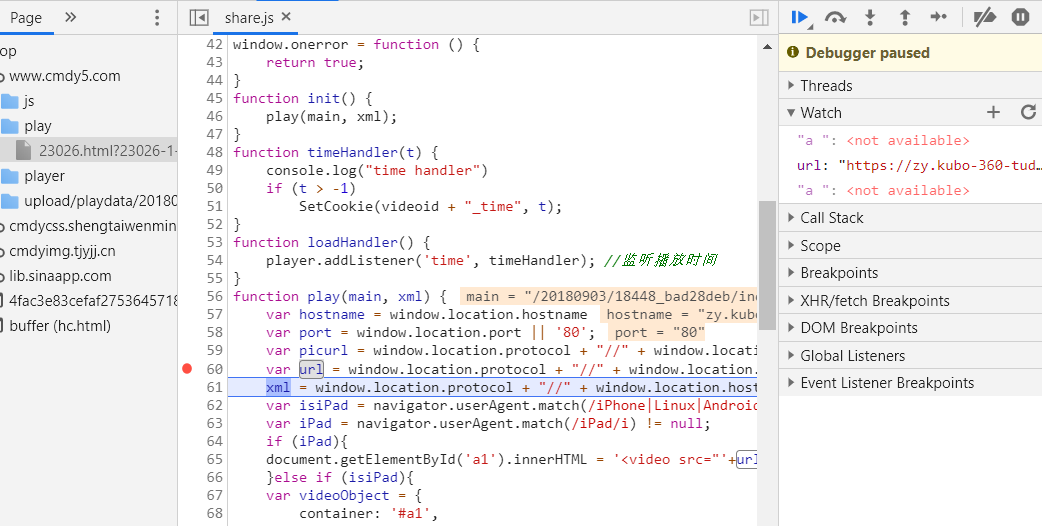
简单看一下就明白了,url变量就是m3u8的地址,在url这里打个中断点准备调试,刷新网页,等一下就会在断点处停下来,这样url的内容就一目了然了。
我测试的url为https://zy.kubo-360-tudou.com/20180903/18448_bad28deb/index.m3u8?sign=5ccfa8c3458e3fc929fe93d5bb022065
打开这个网址就会下载一个m3u8文件,文件的内容如下:
1 | #EXTM3U |
这表示刚才下载的m3u8文件还有一个重定向,指向另一个m3u8文件。把这里两个地址组合一下 https://zy.kubo-360-tudou.com/20180903/18448_bad28deb/800k/hls/index.m3u8 ,然后打开新的网址又下载一个文件,内容如下:
1 | #EXTM3U |
这才是真实的TS碎片地址,组合一下地址,就可以直接下载了。比如要下载09c7610a2da003.ts这个文件,打开 https://zy.kubo-360-tudou.com/20180903/18448_bad28deb/800k/hls/09c7610a2da003.ts 就会下载了。
到这里你就可以一个一个把TS视频文件下载下来了,当然这样手动太麻烦,接下来用脚本批量下载。
2 自动解析m3u8文件,获取每一个TS的url
这里用到了一个m3u8解析库 Python m3u8 parser(https://pypi.org/project/m3u8/)。使用也很简单
1 | import m3u8 |
3 下载TS
这里用到另一个python库 requests https://requests.readthedocs.io/en/master/ 。使用也很简单,用get方式就可以了
1 | import requests |
4 合并成一个完整的电影
这里用ffmpeg库,推荐用FFmpeg concat 分离器,这种方法成功率很高,无损合并,但是需要 FFmpeg 1.1 以上版本。先创建一个文本文件filelist.txt:
1 | file 'input1.ts' |
然后:
1 | ffmpeg -f concat -i filelist.txt -c copy output.mkv |
完整的代码
1 | import sys |
效果
目前只是单线程顺序下载,浪费了大量的宽带。后期需要加入多线程加速。


